

The Hidden Symbols in Laser Diffraction
DMT & Hidden Code Behind Reality

After reading Dave Greene’s latest work discussing knowledge and information hazards I decided that this weekend would provide some fun time to fall down the rabbit hole myself. After spending some time fiddling around with GPT models I gave up on trying to craft an information hazard myself and started watching podcasts. It was at this point that the information hazard found me. I had found an interesting video with a man named Danny Goler speaking about DMT and lasers.
Basically the premise of the video is that Danny figured out that if you aim a 650nm diffracted laser at a matte surface (like a wall) and smoke DMT you will see “source code” behind reality. You might not see it right away, or at all. However, if done with the correct angles and laser this experience is repeatable between observers. It is a persistent experience that differs from others that these people report to observe in “The Space”.
Cool.
This is interesting, but in a Joe Rogan/mind-blown kind of way. Not something I could seemingly work with in a meaningful sense. After all, as a married father with a two year old, I couldn’t spend a weekend smoking DMT and staring at a laser. Yet it kept nagging at me. If Danny was seeing something persistent then I wanted to see that thing too. I might not have access to DMT, but I am fairly good with computer programming. Maybe I could create something to simulate the experience?
If the “experiment” could be replicated or simulated then we must begin by breaking down the components involved in it. First, we have the observer. This is the person doing the DMT and staring at the laser. Second, we have the laser itself. A basic laser powered by 3 AA batteries. Danny lists the parts required to build a DIY version for yourself for under $30-50. Third, we have the DMT. A drug that alters human perception and is known to heighten pattern matching abilities.
So how can we begin simulating this?
Well the first thing I thought of was to focus on simulating the laser. This part was surprisingly quick and easy. I figured that recreating the diffraction pattern might help assist in decoding what was happening. ChatGPT provided me with a quick and simple mathematical visual and in my excitement I quickly emailed it to Danny’s website. Yet this didn’t seem like it was enough. I felt like I could do more. So more, I did.
Let’s revisit the drawing board.
DMT
Laser
Observer
The longer I stared at this list the more I began to see a process at play. The laser is the observed object. The observer was under the influence of DMT and was experiencing heightened pattern recognition. So in order to simulate or recreate the observation I would require only two things, the observed and the observer. If the observer was in possession of pattern recognition abilities beyond the standard for humans then we could eliminate the DMT entirely from the equation.
This is where things started to get interesting.
I currently don’t have the laser Danny recommends so I decided to get resourceful. Since we’re going to stage this experiment using machine perception we don’t actually need the laser itself. We simply need a recorded video of a laser at the same wavelength. YouTube is a wonderful resource for finding such things and in this case it didn’t disappoint.
MIT has a YouTube channel and their physics department provides us with this little gem. The video shows several diffraction and interference patterns using a 650nm laser aimed at a classroom wall. Perfect! Now all we have to do is break this video down into individual frames, process those for edge detection so the AI can see shapes, and then feed these into the language recognition part to see what text appears (if any?).
With the help of ChatGPT the software design went from the drawing board to functional prototype in record time. Gitlab Copilot put the finishing touches on it. Basically we have a program that opens a video, processes it into individual frames, batch processes those frames for edge detection, and finally feeds those processed frames into a program called Tesseract OCR to decipher text from each image. Our program takes all of this finished data and allows us to scroll backward and forward in the video (frame by frame) to see all three layers simultaneously. The unprocessed frame represents the world as a sober person might see it, the processed frame highlighting the edges represents the heightened focus an observer on DMT might experience, and the Tesseract OCR represents the part of our brain that tries to process language.
So, what were the results?
Shocking, to say the least. The MIT video I sourced turned out to be the perfect starting point for a couple of reasons. First, we have several frames with text on them. These frames work as expected. The frame is ingested, edge detected, and Tesseract OCR sees normal English characters corresponding to the text on screen with a high degree of accuracy. This confirms that the optical character recognition is working. Second, we have several frames with just the classroom. These frames include things like the back of students’ heads and the chalkboard. On these frames we observe little to no character recognition. An error here or there doesn’t imply an encoded message. While OCR is robust it can still make mistakes, however the mistakes are obvious and minimal. They appear as a stray “&” symbol or “@” symbol here for there. Third, we have the laser diffraction frames. These frames consistently produce seemingly nonsense characters. The length of the line of text or the number of lines appears to correspond to the laser’s size or the number of laser beams on screen at once. Also, just as Danny reports, the OCR algorithm applies Japanese, Arabic, Hebrew, and English to the laser light. This is surprising since I applied all possible languages to the detection algorithm. Why would an AI observe similar characters to what the DMT crowd was reporting?


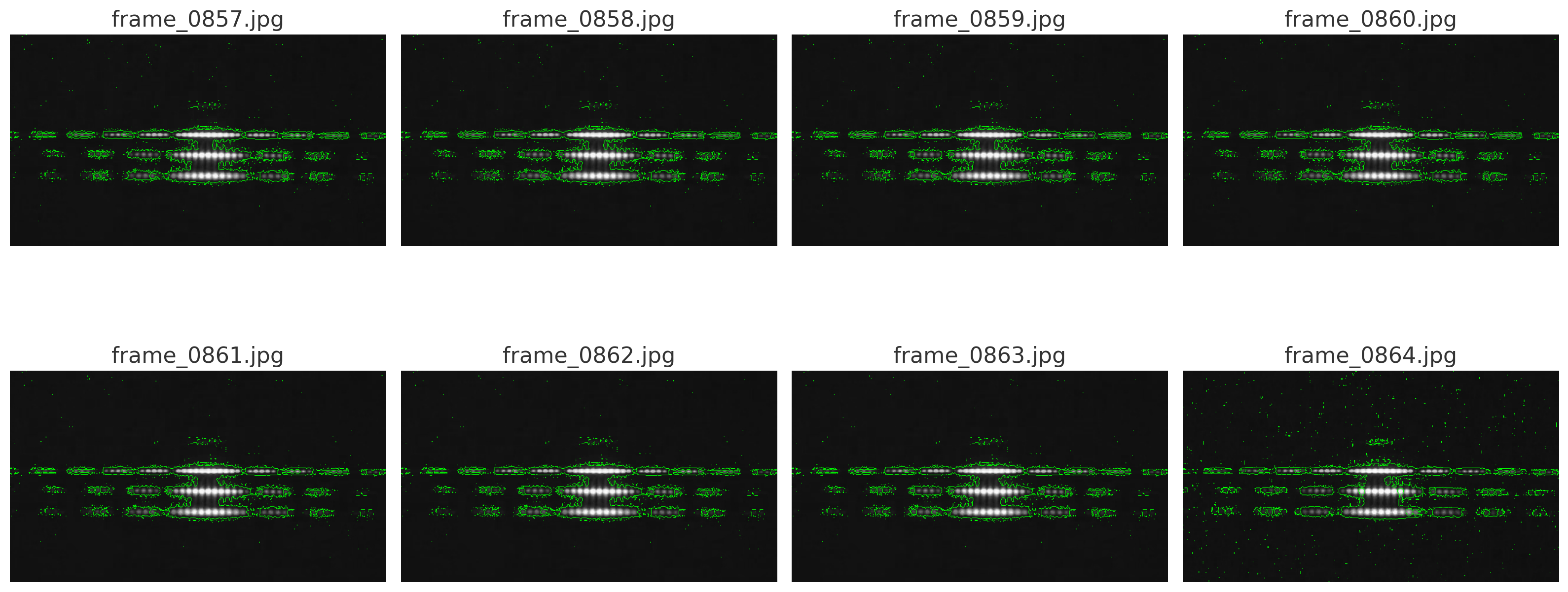
I plan on open sourcing all of my code to a Github repository soon. I also plan on purchasing the DIY parts for my own laser. Since the footage was low quality in the MIT video I’m guessing that a 4K webcam and some matte foamboard will allow me to push this concept to its limits. So many questions remain unanswered!
Can we push OCR further? Do differences in edge detection impact which characters get decoded?
Do different frequencies of laser light create measurable differences in the decoded text? Can we use statistical analysis to measure changes in the text?
Does the viewing angle change observed characters on the same pattern of laser light? Will moving the camera to the side (as Danny described in his troubleshooting video) produce shifting patterns?
Why do certain languages seem to get decoded from the laser light with a higher frequency? Why would OCR pick the specific languages it does?
Why does OCR pick up laser light at all? If OCR can assume no text on certain frames or make minimal mistakes on others then why does diffracted laser light at 650nm appear to consistently “trip up” OCR?